2024.06.21
Jest Architecture
https://www.youtube.com/watch?v=3YDiloj8_d0 (opens in a new tab) (2018.11.20 업로드) 내용 정리
$ jest my-test.jsJest가 위와 같은 명령어를 처리하는 과정을 살펴보고 개괄적인 아키텍처에 대해 알아보자
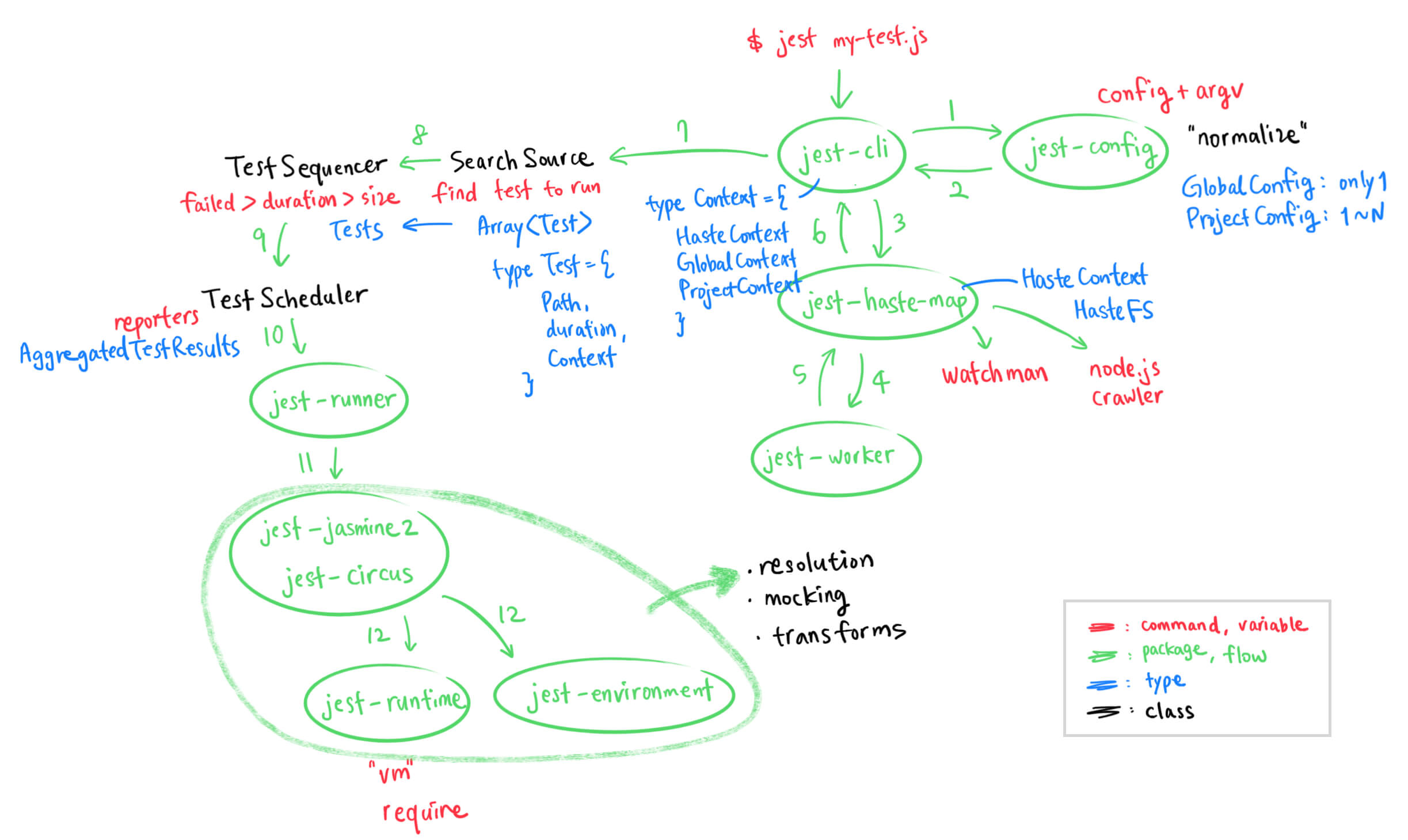
STEP 1
jest-cli
👉 어떤 테스트를 실행하는가?
- 첫 실행 지점
jest-config실행
STEP 2
jest-config
👉 무엇을 실행하는 명령어인지 알아냄
-
(1) config + argv
- config: package.json, jest.config.js 등의 설정파일을 읽고 설정 취합
- argv: 명령어를 실행하는데 필요한 인자를 찾음
-
(2)
jest-config에 정의되어 있는 normalize 함수 실행
(1)에서 취합한 데이터를 정규화하고 2가지의 설정 객체를 생성
- GlobalConfig
- Jest를 실행하면 1개만 생성됨 (언제나 1개)
- ProjectConfig
- 프로젝트별로 생성 가능(1 ~ n개)
- 브라우저 환경을 테스트 하고 싶으면 JSDOM 사용
- Node 런타임에서 구동하는 서버를 테스트하고 싶으면 Node.js 환경 사용
몇 개의 worker를 사용할 것인지
어떤 테스트 프레임워크를 사용할 것인지
어떤 타이머 시스템을 사용할 것인지
어떤 모듈을 mock/unmock 할 것인지 등을 결정
Jest는 매우 많은 설정 옵션들을 제공함
너무 많은 옵션들을 제공하는 것이 코드스멜처럼 보일 수 있고, 여기서 비롯되는 문제들(유지보수가 어렵다거나, breaking changes가 많다거나)을 우려할 수 있지만
실제로 이런 문제들이 발생하지는 않음
나중에 보겠지만 이러한 패키지 아키텍처를 사용하면 패키지들을 swap 함으로써 (swap out pieces) 하여 설정 옵션들이 서로 영향을 미치지 않을 수 있음
STEP 3
jest-haste-map
👉 프로젝트 내의 파일 시스템을 읽고 파일간 의존관계 파악
- 테스트를 정말 빠르게 실행하기 위해
- dependency resolution을 위해
- 파일의 변경 사항에 따라 영향을 받는 테스트 알아내기 위해
→ 정적 분석 실행
프로젝트에 들어있는 파일들이 무엇인지, 파일간의 의존 관계가 어떻게 되어있는지 파악 프로젝트 내의 모든 파일을 읽고, 의존관계를 파악하기 때문에 매우 time intensive한 프로세스
의존관계를 파악할때는 각각의 파일들로부터 require, import, export와 같은 구문들을 추출하고 트리 구조로 의존관계를 정리, 트리를 순회하면서 의존관계를 파악함
생성되는 결과물의 타입정보
- HasteContext
- HasteFS (FS = File System, 모든 파일 시스템과 의존관계를 나타내는 리스트)
- Map<Path, Module>
- { id, mtime, number, Array<string> }
- id: module id
- Array<string> : 의존성 배열 리스트haste?
페이스북에서 일할 당시 쓰던 모듈 시스템의 이름
common.js를 쓰기 이전에 쓰던..
어떻게 저장소(repo) 내의 파일 시스템과 의존관계를 파악하나?
watchman
파일 시스템 분석에 특화된 모듈
- 폴더에 어떤 파일이 있는지 전부 리스트업 해줌
- 파일 시스템의 변경사항을 추적 (변경이 발생한 파일만 리스트업해서 알려줌)
jest-haste-map 내부적으로 캐싱을 하기 때문에 전체 파일 시스템을 읽고 변경사항을 추적하는 작업을 매번 하지는 않음
캐시가 없거나, 요청을 받았을 때에만 실행
만약 watchman이 설치되어있지 않다면 node.js crawler사용
Linux 시스템에서는 crawler를 사용해도 괜찮음. crawler가 충분히 빠르게 실행되기 때문에
그러나 Window 시스템에서는 crawler를 custom implementation 한 것 처럼 사용하기 때문에 속도가 느림
watchman이 없으면 테스트를 실행할때마다 전체 파일 시스템을 읽어야 함
테스트 실행 속도가 느려졌다면 watchman을 설치해보기 바람
STEP 4 ~ 6
jest-worker
👉 의존관계를 빠르게 파악하기 위해 특화된 패키지
리스트업된 파일을 jest-worker에 넘겨주면 모든 가용 자원(e.g. CPU)을 사용해서 파일간의 의존 관계 메타데이터를 알려줌
jest-worker가 결과물을 jest-haste-map에 넘겨주면 jest-haste-map은 jest-cli에 넘겨줌
위 과정을 마치고 모든 결과물 취합했을때 결과물이 바로 Context
type Context = {
HasteContext,
GlobalConfig,
ProjectConfig
}jest-haste-map의 캐시와 watchman 덕분에 위 과정은 50~100ms 밖에 소요되지 않음
프로젝트 크기가 작으면 50ms 미만으로 소요
jest는 명령어를 파일 경로가 아닌 패턴으로 인식함
jest-haste-map은 저장소 내의 모든 테스트 파일도 찾기 때문에 jest가 테스트를 쉽게 실행할 수 있게 도와줌
STEP 7
SearchSource 클래스
👉 실행할 테스트를 찾음
Context로 부터 받은 파일 정보에서 정규 표현식을 사용, 명령어에 입력된 파일을 찾음
SearchSource 클래스가 주는 데이터 타입
Array<Test>
type Test = {
Path
duration: number;
Context
}테스트의 실행 순서는 알 수 없음 (unordered)
영상 촬영 시점에 SearchSource는 모듈화가 되지 않은 상태 (2024년 현재는?)
당시 Jest 팀의 계획은, SearchSource를 모듈화해서 사용자들이 프로젝트별로 ProjectConfig를 통해 SearchSource 리스트를 지정할 수 있게 하고싶었음
따라서 프로젝트별로 1개 이상의 SearchSource를 가질 수 있게 되는 것.
파일시스템을 탐색해서 테스트 파일을 찾는 것이 아니라, 원격 시스템을 통해 실행할 테스트를 찾을 수 있도록.
SearchSource를 파일시스템의 추상화된 계층이 아니라, 일반화된 모듈로 쓰는걸 의미함
페이스북 내의 Buck 같은 빌드 시스템?에 적용한다거나
로컬 환경이 아니라 remote machine에서 테스트를 실행하고 실행 결과를 받아볼수도 있을 것
STEP 8
TestSequencer 클래스
👉 테스트 실행 순서 결정
SearchSource에서 TestSequencer로 테스트 전달
테스트 실행 순서를 알기 위한 몇가지 휴리스틱이 적용되어 있음
휴리스틱 : 문제를 해결하거나 불확실한 사항에 대해 판단을 내릴 필요가 있지만, 명확한 실마리가 없을 경우에 사용하는 편의적 발견적인 방법. 다른 말로 표현하면 쉬운방법, 어림짐작
개선의 여지가 많으니 PR 보내달라
TestSequencer는 테스트 실행 순서를 정하는 기준 (CPU 사용량에 관계 없이)
캐시가 있다면 predictable assumption을 할 수 있지만 캐시가 없다면 그다지 유용하지 않음
📌 failed > duration > size
- 테스트가 과거에 실패했는가? (failed)
실패한 기록이 있다면 해당 테스트를 먼저 실행
- 실행 소요시간이 긴가? (duration)
- 느린(=소요시간이 긴) 테스트를 먼저 실행하고 빠른(=소요시간이 짧은) 테스트를 나중에 실행
- CPU를 최대한 활용하기 위한 전략
- 파일 사이즈 (size)
- 단순하게 생각했을때 1000줄짜리 테스트 코드는 50줄짜리 테스트보다 더 많은 시간이 필요함
- 여기서의 맹점은 코드의 양은 적지만(5줄) 실제로 코드가 사용하는 모듈이 매우 큰 자원을 필요로 하는 경우 의도한대로 동작하지 않을 수 있음
이러한 휴리스틱 때문에 테스트 실행 순서가 매번 바뀜
테스트를 반복해서 실행할수록 실행 소요시간에 대한 예측도가 올라가기 때문에 보다 일관된 실행순서를 가지게 됨
개선 여지가 있는 부분들
- 테스트별 실행 소요시간을 더 정확하게 예측할 수 있는 방법?
예를들면 1~7 과정에서 얻은 데이터들을 활용, 정적 분석을 통해 테스트 파일에 얼마나 많은 test, it, describe 가 있는지 파악하고 소요시간이 긴 테스트를 먼저 실행
- 코드 수정에 따른 테스트 코드의 우선순위를 알 수 있는 방법? (테스트 스케줄링)
수정한 코드에 따라 중요한 테스트를 먼저 실행하고 덜 중요한 테스트는 나중에 실행해서 빠른 피드백을 줄 수 없을까?
TestSequencer에서의 성능은 단순히 테스트의 실행 속도만 의미하는게 아니라 perceived performance를 의미하기도 함
perceived performance는 UX에 대한 것
예를 들면, 이전에 실패한 테스트를 나중에 실행하는 것은 말이 안 됨
따라서 실패했던 테스트를 먼저 실행하는 것은 매우 좋은 휴리스틱이 될 수 있음
사용자 입장에서는 실패한 테스트를 토대로 수정을 했을때 해당 테스트의 결과를 먼저 보고 싶을 것
STEP 9 ~ 10
TestScheduler 클래스
👉 테스트 목록과 실행 순서를 토대로 최적의 실행 방법 결정 & 리포트 생성
모든 테스트를 하나의 프로세스에서 실행시킬지 (in band) / 여러 개의 프로세스에 테스트를 분산시켜서 실행시킬지 결정
Jest의 범용성을 위해 (make Jest more generic) TestScheduler 일부 기능을 추상화해서 모듈로 빼냄
그게 jest-runner
ProjectConfig를 통해 jest-runner를 다른 것으로 대체할수 있음
예를들면 puppeteer를 사용해서 Jest를 실행한다거나 할 때.
TestScheduler 에도 휴리스틱이 적용되어 있음
worker 프로세스들을 start up 하는데 긴 시간이 소요된다는걸 알게됨
테스트 수가 적은 프로젝트의 경우 매우 빠르게 실행/종료가 가능
테스트가 10개밖에 안되는데 worker를 10개 실행시킬 필요는 없음
테스트를 실행하는데 걸리는 시간보다 worker를 시작하는데 걸리는 시간이 더 오래 걸림
따라서 테스트가 얼마 없거나, 매우 빠르게 실행할 수 있다는걸 알게 되면 하나의 프로세스에서 전부 실행하도록 함
TestScheduler 에서 실행 방법을 결정하면 그 결과를 jest-runner에 전파함(deleagate)
jest-runner는 jest-worker를 호출함
jest-worker는 실제 프로세스를 생성하고 테스트를 실행하는 역할을 함
jest-worker는 node.js 환경에서 태스크 병렬처리가 필요할때마다 어디서든 사용될 수 있음
병렬처리 기능은 node.js 10의 built-in 기능임
STEP 11 ~ 12
jest-jasmine2
Jest에서 테스트를 작성할때 사용하는 API들의 내부적으로 jasmine을 사용하고 있음
예전에는 jasmine을 그대로 사용했지만, 불필요한 기능을 전부 없애고 가볍게 만든 뒤 이름을 jasmine2라고 지음
jest-circus
describe, test, it 같은 API들을 제공
트리를 만들고 테스트 실행 순서를 제어하기 위해 flux 아키텍처를 사용하고 있음
테스트 디버깅에 사용됨
jest-runtime
여러 개의 테스트를 같은 프로세스에서 실행하더라도 각각의 테스트는 독립적인 context를 가지고 고립된 환경에서 실행됨
여기서의 context는 앞선 언급한 context와 다름. node.js가 제공해 주는것
vm은 자바스크립트를 고립된 환경에서 실행할 수 있게 해줌
보안이 취약하지만, 테스트 프레임워크에서는 활용하는데 문제가 없음. 실행할 코드를 신뢰할 수 있기 때문에 문제가 되지 않음
vm을 사용해서 context를 생성하면 자체적으로 전역 환경을 지정하고 환경변수를 세팅할 수 있고
JSDOM을 사용할 경우 모든 DOM API을 설정할 수 있으며
node.js의 경우 가짜 node.js 환경을 세팅할 수도 있음
jest-runtime에는 커스텀 require도 들어있음
mocking system도 jest-runtime에서 수행
Jest를 사용하면 런타임에 모듈을 swap할 수 있음
jest.mock을 호출해서 모듈을 mocking하고 나중에 그 모듈을 require하는것이 모두 여기에서 일어남
모킹된 모듈을 가져올지 실제 모듈을 가져올지 판단하는 런타임 시스템임
jest-circus는 jest-runtime 뿐만 아니라 jest-environment도 실행시킴
- resolution
- mocking
- transforms (typescript, babel, …)
context 내에서 실행되는 모듈 시스템을 내에서 글로벌 객체를 어떻게 구현할 것인지
어떻게 동작?
require 함수는 jest-runtime이 vm context에 주입한 것
우리가 모듈을 require 하면 해당 요청은 vm context라는 샌드박스에서 벗어나 jest-runtime으로 돌아가서
요청받은 모듈이 무엇인지 찾고, ProjectConfig의 내용을 참조해서 그 모듈이 transformation 이 필요한지 판단하고, 처리한다
이러한 과정은 동기적으로 처리된다
why?
require 함수는 동기적이고, transformation 은 just-in-time하게 수행되기 때문. (요청이 들어오는 즉시 실행)
만약 비동기적으로 처리할 경우,
테스트를 실행하기 전에 jest-circus 쪽으로 다시 돌아가서 transformation이 필요한 모든 파일을 파악하고 transformation을 해야 한다
사람들이 모듈을 어떻게 포함시키는지에 따라, 어떤 사람들은 require convention을 따르지 않을 수 있기 때문에
의존성 그래프가 정확하지 않을 수 있고, 이 경우 테스트를 실행하기 전에 정확하게 transformation 하는 것이 어렵다
따라서 둘 중 하나를 선택해야 함
- 테스트를 실행하기 전에 모든 transformation이 필요한 모든 파일을 transformation 할지
- 필요한 시점에 transformation 할 지( just-in-time)
jest의 실행 처리 곳곳에 캐시가 적용되어 있음
테스트를 두번째 실행했을때 50%까지 빨라지는데 그 이유는 transformation이 전체 테스트 수행 시간의 50% 이상을 차지하고, transformation에도 캐시가 적용되어 있기 때문임.
TestScheduler는 모든 실행 결과를 받아올 수 있는 callback이 정의되어 있음
테스트 수행 결과는 어떻게 얻을 수 있나?
TestResultjest-jasmine2, jest-circus는 테스트가 완료되면 TestResult 객체를 업데이트 함
TestResult에는 테스트 이름, 성공/실패 여부, 실행 시간, stack trace 등 많은 정보가 들어있음
중요한건 TestResult가 JSON 으로 serialize 될 수 있어야 한다는 것
왜냐면 이 데이터를 프로세스간에 주고받을 수 있어야 하고, 데이터를 최대한 심플하게 관리하기 위함임
TestScheduler는 test reporter를 생성하기 위해 데이터를 취합함. 이를 위해 callback을 가지고 있음
테스트가 완료되면 callback을 호출, 데이터를 취합.
AggregatedTestResult // mutable한 js 객체